

半夜手機響起,你打開網站卻只看到 502,這種感覺像店面鐵門被拉下,但你連哪裡停電都不知道。小團隊最怕的不是故障,而是故障發生時沒有線索,只能靠猜。
這篇把 WordPress 監控告警 拆成三件事,Uptime(可用性)、錯誤率(品質)、慢查詢(效能),提供兩條可以落地的路線,你可以先小步快跑,之後再擴充。
先把監控訊號定好,Uptime、錯誤率、慢查詢要看什麼
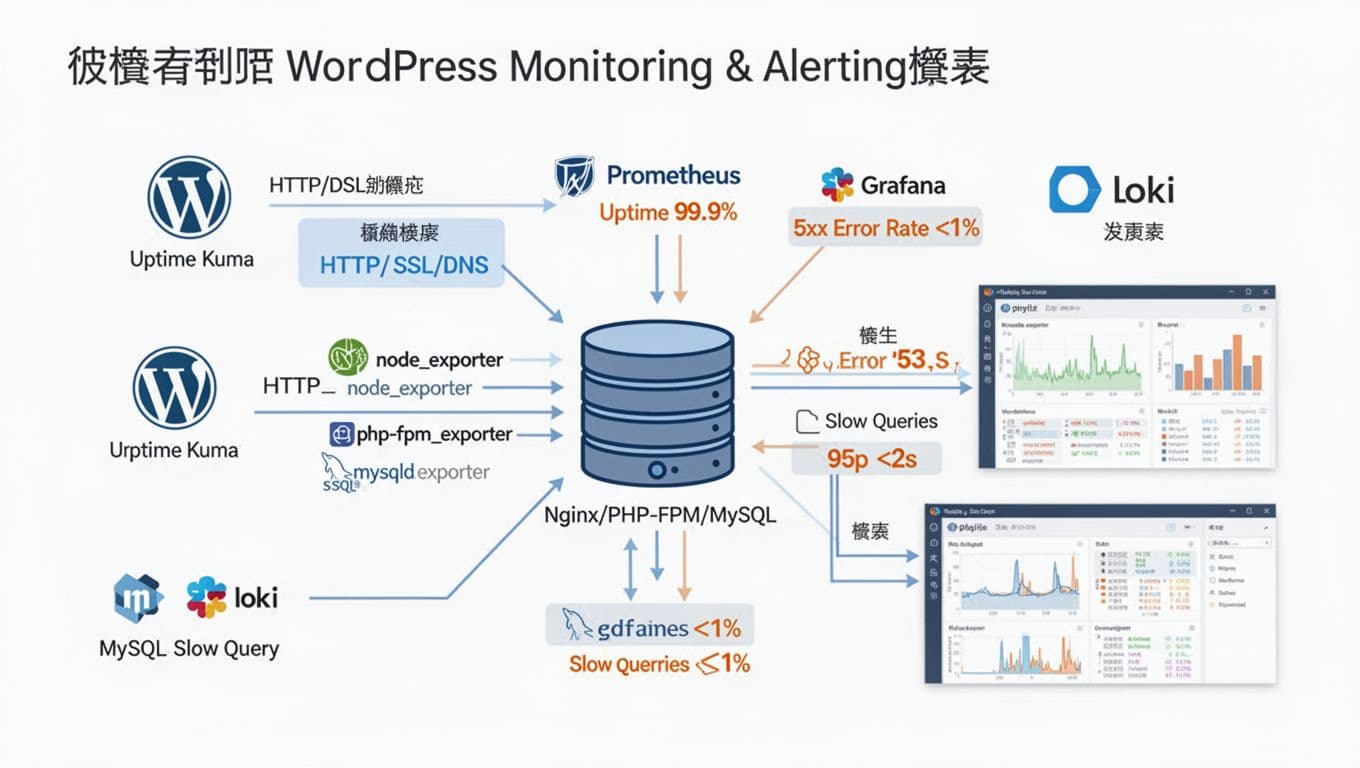
小團隊的監控不要貪多,先抓「會讓使用者直接受傷」的訊號。Uptime 不是只有 Ping 通就好,建議至少包含這四種檢查:
第一,HTTP 狀態碼,以首頁與結帳或登入頁為主,觀察 200/3xx/4xx/5xx。第二,SSL 到期,提早 14 天告警,避免續證忘記。第三,DNS 解析,有些事故不是主機掛,而是 DNS 走錯。第四,關鍵頁面內容比對,用關鍵字確認頁面不是被 WAF 擋住或回到維護頁(例如比對「加入購物車」「付款」等字串)。
多點檢測也很實用,因為「我這裡能打開」不代表使用者能打開。做法很簡單,在不同地區放 2 到 3 個探針(不同 VPS 或不同監測節點),同一個 URL 由不同地點打,才能分辨是你站台問題,還是某區網路問題。想快速上手 Uptime Kuma,可參考這篇 Uptime Kuma 30 分鐘上手。
告警分級也要先定義,否則訊息會淹沒你:
- P1(立刻處理):連續 2 次檢測 5xx 或整站 404/502,付款頁不可用,SSL 已過期
- P2(當天處理):5xx 率升高,慢查詢暴增,wp-cron 停擺
- P3(排程處理):磁碟逐日上升,備份失敗一次,外掛更新可用但有警告
通知通道建議同時準備 Slack 或 Email,再加一個手機可收的通道。LINE 若要做告警,多半會走 Messaging API 或 LINE WORKS Bot,記得把「維護視窗」與「靜默」打開,像更新外掛這種可預期事件,不該一直吵人。
落地路線 A,全開源小成本(自架)的監測與告警
開源路線的優點是彈性大、資料留存自己掌控,缺點是要有人能維護。以 1 到 5 個站,小團隊常見做法是一台便宜 VPS 放監控(每月約 US$5 到 15),目標是「今天上線基本監測,之後再補細節」。
基本組合可以是 Uptime Kuma + Prometheus + Grafana,再加三個 exporter:node_exporter(主機 CPU/RAM/Disk)、mysqld_exporter(MySQL 指標)、php-fpm_exporter(PHP-FPM 佇列與狀態)。Prometheus 最小可複製的抓取片段可以長這樣(把主機名換成你的):
- job_name: 'node'static_configs:- targets: ['wp-01:9100']
錯誤率怎麼做才有「比例」概念?建議做一個 5xx 率面板,公式是 5xx 率 = 5xx 請求數 / 全部請求數,以 5 分鐘或 10 分鐘滑動視窗看趨勢。若你已經把 Nginx/Apache access log 丟進 Loki,也能用 LogQL 算比例。想要先把 log 做得乾淨,Nginx log_format 可以先從一行 JSON 開始,至少帶出 status 與 request_time:
log_format json_main escape=json '{"time":"$time_iso8601","status":$status,"rt":$request_time,"uri":"$request_uri","ua":"$http_user_agent"}';
慢查詢是小團隊最常忽略的一塊,卻很常是「突然變慢」的元兇。MySQL 建議先開 slow query log,long_query_time 通常從 1 秒起跳(流量大再往上調,避免寫爆磁碟)。設定片段可先用這幾行:
slow_query_log=ONslow_query_log_file=/var/log/mysql/slow.loglong_query_time=1
分析工具可用 pt-query-digest(或先用 mysqldumpslow 做初步聚合)。pt-query-digest 的整理方式可參考 pt-query-digest 過濾慢查詢示例,而 slow query log 的觀念整理可看 slow-query-log 分析流程。告警建議先做兩個:慢查詢數量(每 5 分鐘)與慢查詢延遲 95p(例如超過 2 秒)。同時記得避免記錄敏感資料,像含 token 的查詢參數,或把使用者輸入原文寫進 log。
WordPress 特別點也要顧到。wp-cron 若靠流量觸發,低流量站很容易排程卡住,建議改成系統 cron 觸發 wp-cron.php,並用 Uptime Kuma 的 Push/Heartbeat 概念監測「今天有沒有跑」。外掛造成慢請求時,先用 WP-CLI profile-command 找出最慢的 hook 或查詢,再決定要不要加 object cache(例如 Redis,屬選配),別一開始就把整套堆滿。
落地路線 B,低維運 SaaS(少人力)與混合方案
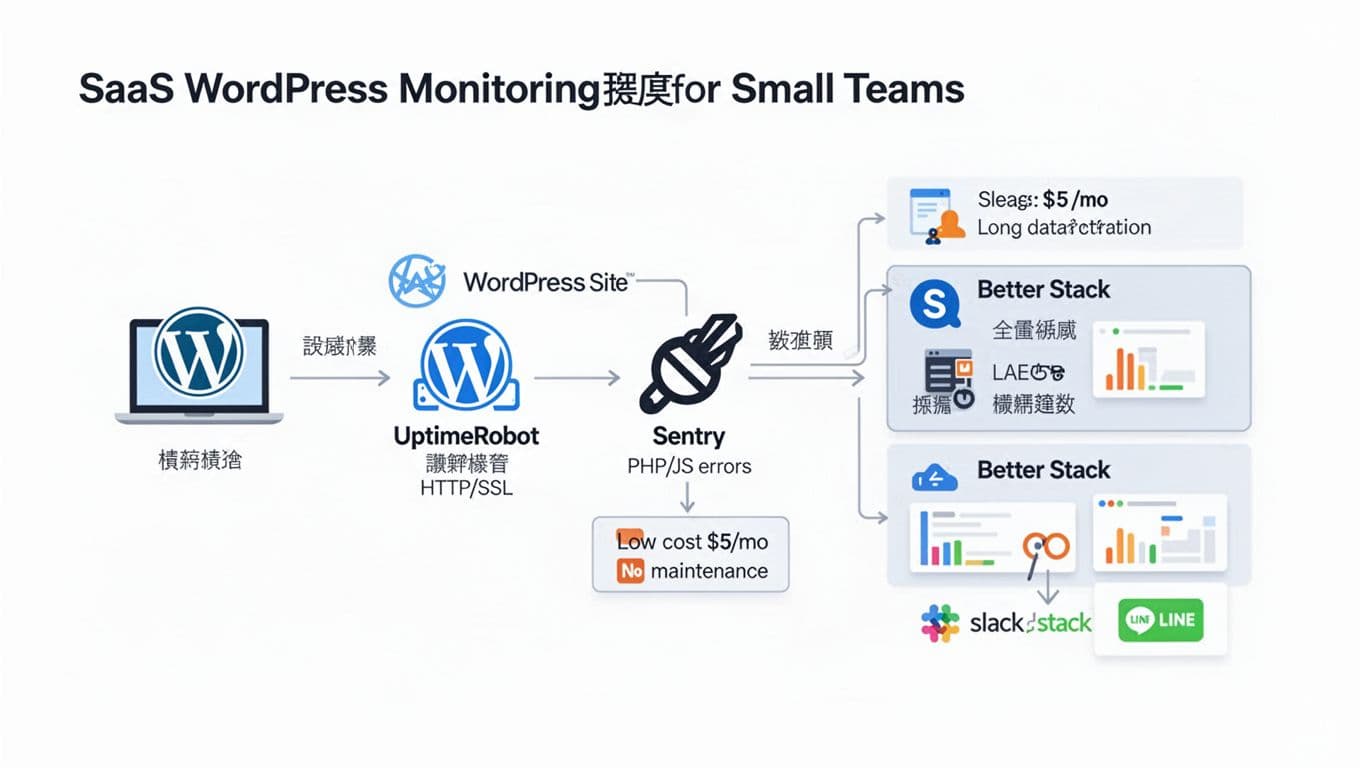
如果你們真的沒有多餘時間維護監控主機,SaaS 路線會更像「租一個煙霧偵測器」,插上就能用。常見搭配是 UptimeRobot 或 Better Stack 做 Uptime,Sentry 做錯誤追蹤,再把告警丟 Slack/Email。Better Stack 的 Uptime 玩法可先看 Better Stack 的 uptime monitoring 說明 了解能做到哪些檢測(狀態頁、多頻率檢測、事件時間線等)。
錯誤率這塊,Sentry 特別適合小團隊,因為它能把「哪個頁面、哪段程式、哪個外掛」直接串起來。WordPress 端可用 Sentry for WordPress 外掛 同時收 PHP 錯誤與前端 JS 錯誤,這對「使用者點了沒反應」的問題很有幫助。伺服器端仍建議保留 Nginx/Apache 5xx 的觀測,因為這是最直觀的品質指標。
兩條路線怎麼選,可以用這張小表先決策:
| 項目 | 路線 A 全開源自架 | 路線 B 低維運 SaaS |
|---|---|---|
| 月成本 | 伺服器費用為主 | 訂閱費用為主 |
| 維護負擔 | 需要更新、備份、容量管理 | 幾乎不用管主機 |
| 留存 | 硬碟多大留多久 | 依方案常見 7 到 30 天起 |
| 擴充彈性 | 高,可客製化 | 中,受方案與功能限制 |
不管開源或 SaaS,安全與隱私都別省。API key 請放在環境變數或密鑰管理,不要寫進 repo。權限用最小化,像只允許送 metrics 的 token,不要給管理權。Log 與 trace 要做脫敏,至少把 Authorization header、Cookie、含個資的參數去掉,避免「監控把資料外洩」。
小團隊也可以走混合:Uptime 用 SaaS(省探針與多點),指標與慢查詢用自架(留存自己掌控)。到 2026 年,這種混搭很常見,因為它最省人力,也不會把所有資料都交給單一平台。
結語,小團隊先把告警做得「可信」就贏一半
把 Uptime、錯誤率、慢查詢三件事串起來,你就不再是靠直覺維運,而是用訊號做決策。先從最少的檢查開始,讓告警變成 可信 的提醒,不要變成噪音。
如果你希望有人把這套 WordPress 監控告警 直接落地到你的站上(含維護視窗、告警分級與儀表板),可以到 WPTOOLBEAR 看維護方案與代管選項,讓團隊把時間花在產品與內容上。




